学习Word2Vec中的Skip-Gram模型
Word2Vec 之 Skip-Gram
Word2Vec 模型常用来将词语、句子转换成向量,方便进一步完成文本的分类、聚类等任务。Word2Vec模型又分为 CBOW 和 Skip-Gram 两种实现,有关传统向量化方法和word2vec方法的文章,我觉得下面两篇容易理解:
- A Gentle Introduction to the Bag-of-Words Model https://machinelearningmastery.com/gentle-introduction-bag-words-model/(主要介绍词袋模型)
- https://easyai.tech/ai-definition/word2vec/(这篇相当于简单介绍Word2Vec)
- 理解 Word2Vec 之 Skip-Gram 模型-知乎专栏 https://zhuanlan.zhihu.com/p/27234078(讲Word2Vec,针对skip-gram这种训练模式)
尝试用keras实现skip-gram模型
我这里的实现很基础,因为完整方案里面的“负采样”、“层次softmax”等训练技巧没琢磨明白
体验正式的Word2Vec还是使用第三方库gensim里面的 gensim.models.Word2Vec
我的实现分为三个步骤:
- 构造训练数据
- 构造并训练模型,获得词向量
- 检验词向量效果
构造训练数据
这部分工作是在一个GitHub已有项目基础上完成的,原始数据来源http://mattmahoney.net/dc/
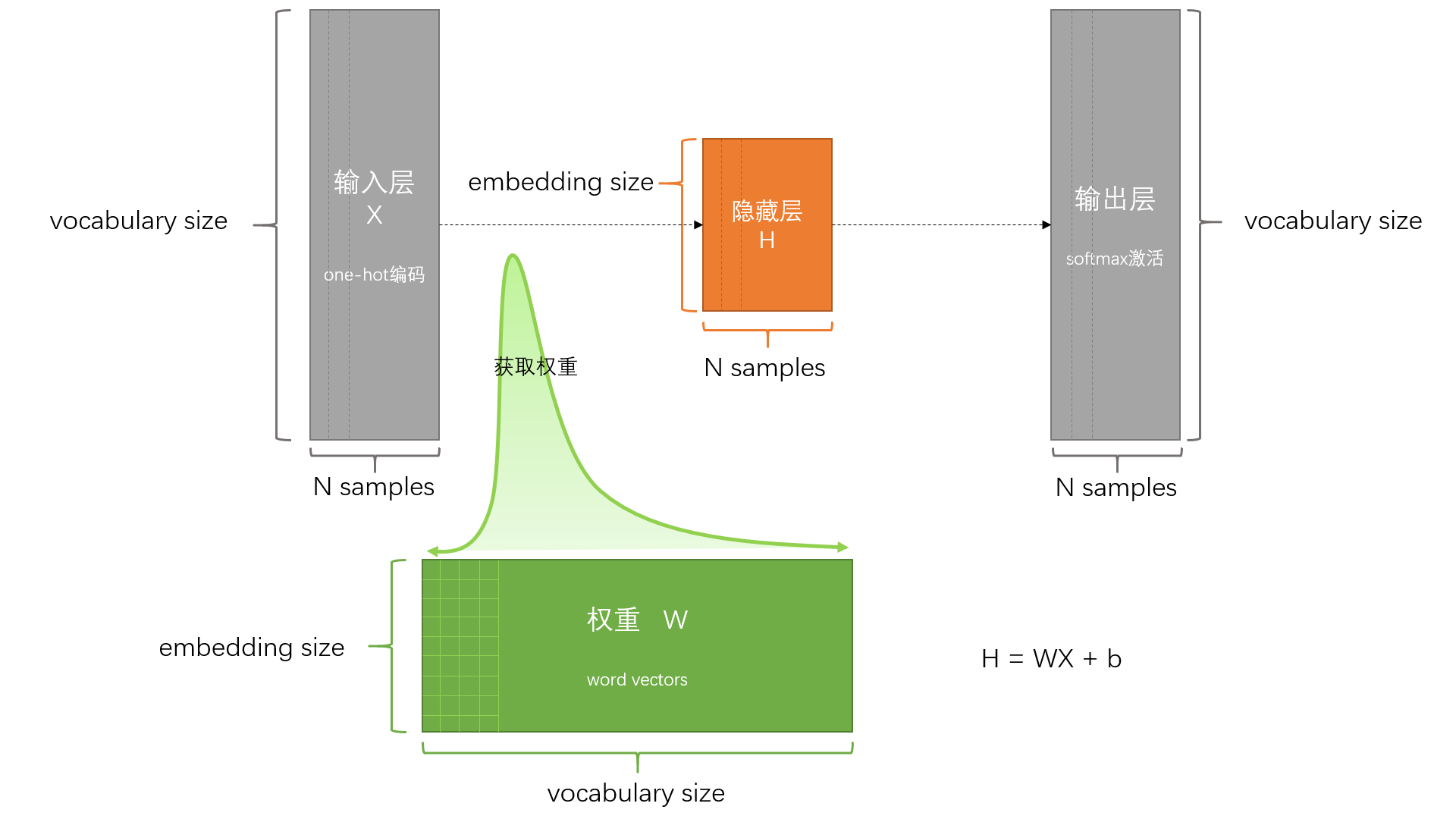
skip-gram是用一个词去预测它前后的其他词语,所以就需要按照 [词语, 旁边词语] 的形式来构造数据集,其中 词语 是输入,旁边词语 是输出。
词语用 one-hot 编码表示,假设有50000个词汇,那么一个词语就会表示为一个包含50000个元素的列表。如果一共有3840000个词语用作输入,那么完整的输入就是一个3840000行50000列的稀疏矩阵,输出也会是同等规格的一个矩阵。
构造并训练模型,获得词向量
模型分为三层,输入层,隐藏层和输出层,输入层维度为词汇数量50000,隐层维度设置为128,输出层维度和输入层维度相同。输入层和隐藏层的权重矩阵就是最终要获得的词向量。
# 定义模型
projection_input = Input(shape=(vocabulary_size,), name="projection_input")
projection = Dense(units=embedding_size, name="projection")(projection_input)
output = Dense(units=vocabulary_size, activation="softmax", name="output")(projection)
model = Model(projection_input, output)
# 训练模型
model.compile(optimizer="adam", loss="categorical_crossentropy")
history = model.fit_generator(data_generator(), steps_per_epoch=3840000//batch_size, epochs=15, verbose=2, callbacks=[
EarlyStopping(monitor='loss', min_delta=0.0001, patience=2, verbose=0, mode='auto', restore_best_weights=True)
])
检验词向量效果
取16个词语的向量,找出和每个词语最相似的8个词,不包含词语自身,观察比较相似词的相似程度。
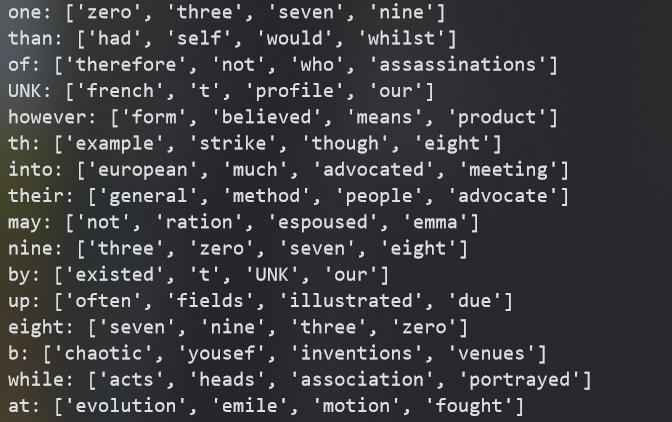
可以发现数字如:eight, zero等的效果还是可以的,但其他词语的效果就不怎么样了
这里放上原GitHub项目的作者用Tensorflow实现的效果(使用了负采样),供对比

实现代码
https://github.com/nice-future/implement-skip-gram-with-keras