基于MovieLens数据集使用协同过滤实现影片推荐
应用延伸
- 基于用户搜索记录实现搜索关键词推荐
- 基于用户浏览记录实现文章推荐(猜你喜欢)
协同过滤原理(User-Base)
假设有 5 部影片(5个标签){A, B, C, D, E};有3名用户对应他/她喜欢的电影 A, B, C, … ;现在要给第一名用户推荐影片。
若:
用户 a 喜欢电影 {A, C, D},用户 b 喜欢电影 {A, C, D, E},用户 c 喜欢电影 {A, B, D, E}
则:
构建行向量 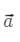
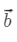
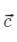
计算:
a b 间的余弦相似度 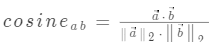
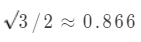
a c 间的余弦相似度 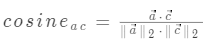
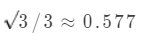
假设相似度高于 0.8 判定为“邻居”,则认为用户 a 和用户 b 是“邻居”,所以将用户 b 喜欢,且用户 a 未作 5 分评价的影片推荐给 a (此处不考虑 a 已对影片作低于 5 分评价的情况)
数据集
规格
This data set contains 10000054 ratings and 95580 tags applied to 10681 movies by 71567 users of the online movie recommender service MovieLens.
处理
测试只使用数据集中的 ratings.dat 文件,文件中的数据格式为:
1UserID::MovieID::Rating::Timestamp
首先需要构建一份用户喜爱的电影清单,然后基于这份历史数据做推荐。
从
ratings.dat文件中过滤出所有评分为 5 (最高)的记录,并按UserID合并。现在得到一个集合,即每个用户
UserID对应着它所有评分为 5 的电影MovieID将集合输出到新的数据文件
user-5-star-movies.txt中,文件的数据格式为:1UserID::5StarMovieID0,5StarMovieID1,5StarMovieID2,...
实现流程
- 读入文件
user-5-star-movies.txt,每一行为一名用户喜爱的一系列电影。根据 原理 所述,将每一行的电影ID转换成向量(如:影片ID为 111 则将第 111 个位置标记为 1,最后剩余的位置用 0 填充)。 - 查找最大影片ID+1 得到列数 n,共 m 行数据组成 m*n 矩阵 X,以矩阵运算替代 m2 次向量遍历运算以提高效率,矩阵十分稀疏,可以用稀疏矩阵
scipy.sparse.coo_matrix形式存储数据以节省空间。 - X 的转置矩阵
scipy.sparse.coo_matrix.transpose记为 Y ,X 和 Y 进行矩阵乘法scipy.sparse.coo_matrix.dot运算得到求余弦相似度的分子部分numerator。 - 对矩阵 X 按行求二范数
scipy.sparse.linalg.norm,对矩阵 Y 按列求二范数,得到求余弦相似度的分母部分。 - 分子
numerator依次除以两个二范数(依次向行、列方向广播)得到 m 条记录两两间的余弦相似度consine。 - 按行取余弦相似度矩阵的排序后索引
numpy.argsort,根据设置的阈值threshold和邻居数量n_neighbors得到每一条记录对应的邻居集合neighbors。 - 每条记录对应的向量 Xi· 减去它对应的邻居向量
neighbor取结果向量diff中所有 -1 值所在的位置即为该条记录的推荐影片ID
另外一提
若用户数量较大,可以将矩阵 X 按一定步长 step 划分为一个个的子矩阵分批和完整矩阵 Y 运算,合并每个批次的结果即为最终结果,以此进一步减少每次的运算压力。
参考资料
https://www.cnblogs.com/luchen927/archive/2012/02/01/2325360.html
代码实现
(尚未上传)