极简电影问答系统
*这是一次作业的记录,数据及实现思路均按要求参考自 https://blog.csdn.net/appleyk/article/details/80422055
*原作者为 Java 实现,我改为用 python 实现
实现思路
按照任务要求,完整阅读了原作者在CSDN上的教程,整理了一下这一问答系统的实现思路:
其中按照我的理解,原作者对Hadoop和Spark的部署,是用于加速分类器(朴素贝叶斯分类器)的计算,我觉着实现过程中所使用的数据量不大,可以不使用分布式架构,所以我就没有做这一部分的内容。(偷懒加一……)
同时,原作者是基于Java来实现的项目(包括hanlp的调用、neo4j的调用、朴素贝叶斯算法的实现、以及演示部分所使用的SpringBoot框架),我考虑到朴素贝叶斯算法在scikit-learn模块中有封装,而且python实现起来代码会更简洁,所以我使用python来重新实现了这一思路。(偷懒又加一……)
此外,原作者构建了网站进行演示,我觉着复杂程度用加一,所以把这一块也省了,直接使用命令行进行交互。(偷懒再加一……)
综上,我的实现和原作者的实现主要区别如下:
编程语言使用Python。
没有使用Hadoop和Spark。
没有构建网站,使用命令行完成交互。
准备过程
正式实现之前,需要准备好数据和环境。
下载安装第三方库
pyhanlp模块(结合自定义词典进行词性标注)、
scikit-learn模块(构建朴素贝叶斯分类器)、
numpy模块(基本的向量运算)、
py2neo模块(连接本地的neo4j数据库,需要提前安装好neo4j数据库并导入节点和关系数据)
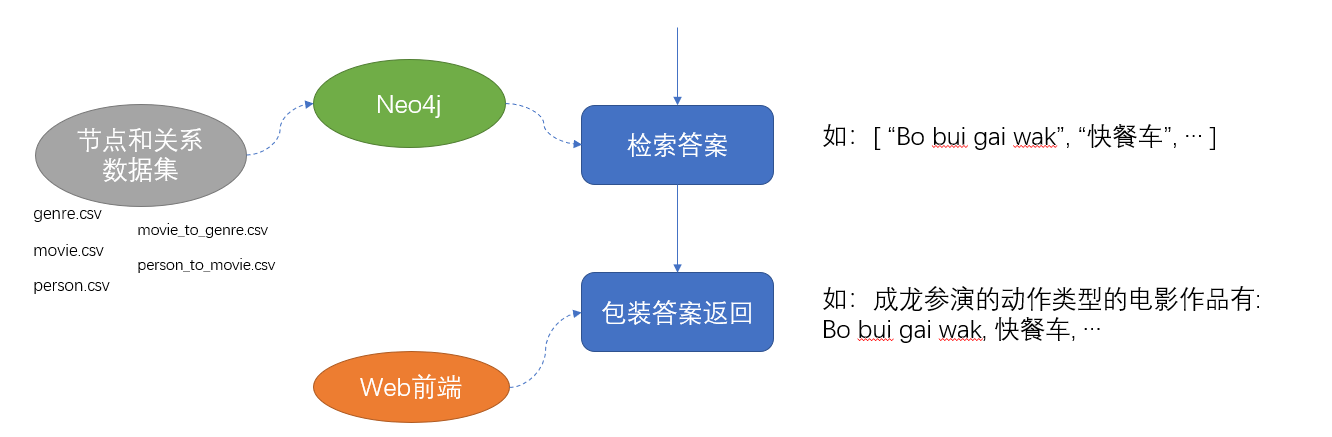
将节点和关系数据导入Neo4j
此部分操作建议直接参考原作者的博客:https://blog.csdn.net/appleyk/article/details/80332911 (需要先安装neo4j,这是一个图数据库,很适合用来存储和检索像知识图谱这类,使用节点和关系来描述的数据)
准备hanlp的自定义词典
原作者思路是使用hanlp将电影名称的词性标注为nm,将演员名称标注为nnt等,这类标注需求显然是Hanlp自带的数据是无法完成的,所以需要构建这三类名词的自定义词典。
原作者博客给出了现成的这几个数据,但我由于没有及时发现,所以这三类名词的自定义词典是基于已有的节点数据提取出来的,对应的代码是 生成自定义词典.py 。
自定义词典的加载推荐使用动态加载的方式,但我使用的是修改pyhanlp配置文件的方式,将自定义词典配置到了pyhanlp中(不推荐,因为这种词性标注需求可能只存在于这次实现)
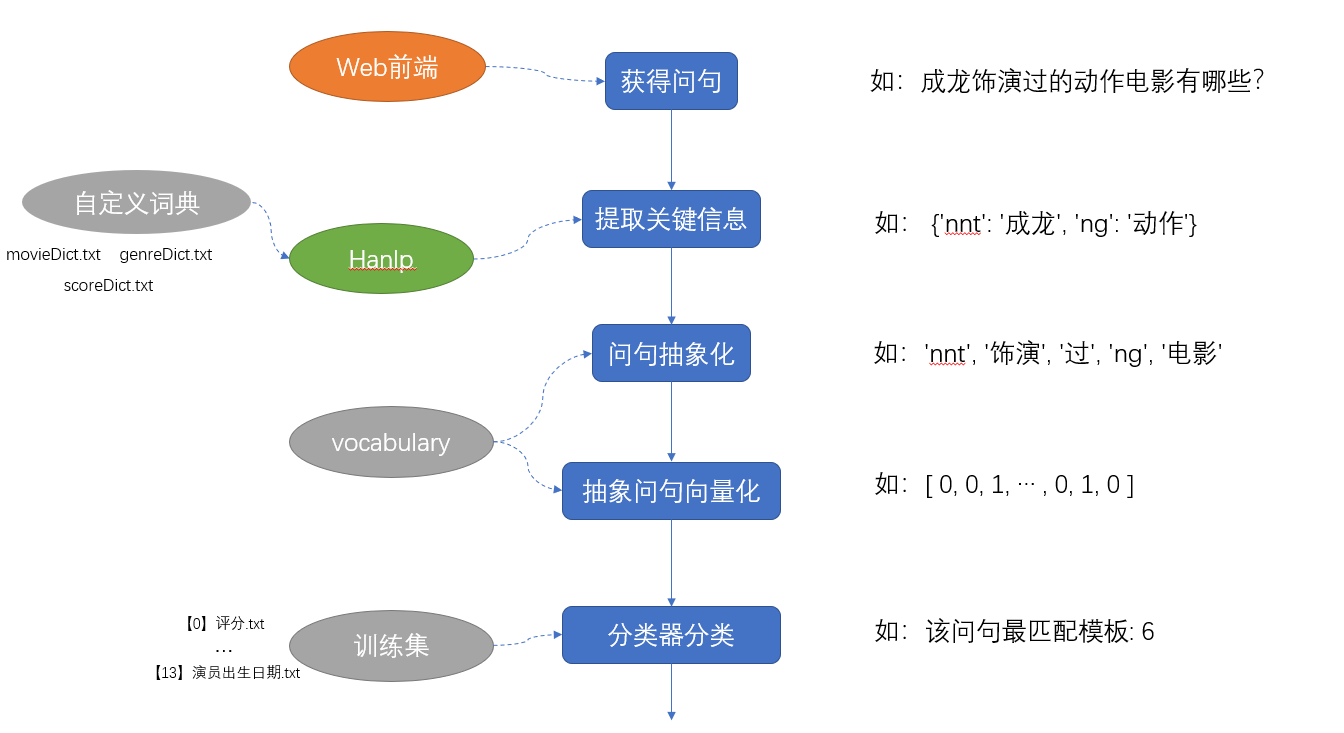
对问句进行分类
问答系统的提问内容是无法预料的,但可以归纳出一些可能的提问的模板,比如“xx电影的评分数据是多少?”、“xx演员和xx演员共同饰演的电影有哪些?”等等,将来,一个模板就对应着 neo4j 的一个查询语句模板,只要发现是这个模板的提问,那么把关键信息(如:电影名、演员名)填入查询语句模板中就可以检索到答案了。
所以接下来的重要任务就是将用户的提问内容尽可能正确地归类到一个模板中,这是一个分类问题。在分类之前,需要对问句做两步的处理,第一步是将问句抽象,第二部是将问句表示为向量。
动态加载需要额外写一部分代码,参考官方示例:https://github.com/hankcs/pyhanlp/blob/master/tests/test_custom_dict.py
将问句抽象
直接对问句进行分类是不好做的,因为电影名称、演员名称数量庞大,但如果把电影名称都用 nm 标记替代,演员名称都用 nnt 替代,问句经过抽象,分类的难度就降低了。
将问句表示为向量
这里可以建立一个词汇表,将频繁出现在问句当中的词语放入词汇表中。词汇表每个词汇都对应一个位置,对于一个抽象过的问句,如果包含某个词汇,那么这个词汇的位置就记为1,否则记为0,这样每个问句都可以表示为形如 [1, 0, 0, ..., 1, 1, 0] 的向量。其中,词汇表原作者也已经给出,我也会上传一份。
开始分类
问句表示成了向量,那么就可以开始分类了。原作者使用的朴素贝叶斯分类算法,我这里也是直接调用封装好的朴素贝叶斯算法。
朴素贝叶斯是有监督的,需要训练集,训练集就是一条条的问句以及每一条问句对应的模板序号。问句转化成的向量就是模型输入,模板序号就是模型输出,用这些数据“教会”模型给问句向量打上模板序号的标签,这样,将来的每一个问句经过处理,都可以被归类到某一个模板中。
获得结果
每一个模板写好对应的neo4j查询语句模板,根据分类结果可以对应到相应的查询语句模板。往模板中填入需要的关键信息,得到完整的查询语句,使用 py2neo 模块执行查询语句就可以得到答案
1from py2neo import Graph
2graph = Graph("http://localhost:7474", username, password) # 连接neo4j数据库
3result = graph.run("<完整的查询语句(Cypher语句)>").data()
数据库查询的结果可以处理成一个列表,但干巴巴地返回一个列表显然不太友好,所以可以给每个模板设置一个开头说明,根据模板编号为结果增加一个更加友好的开头,然后回显在终端中。
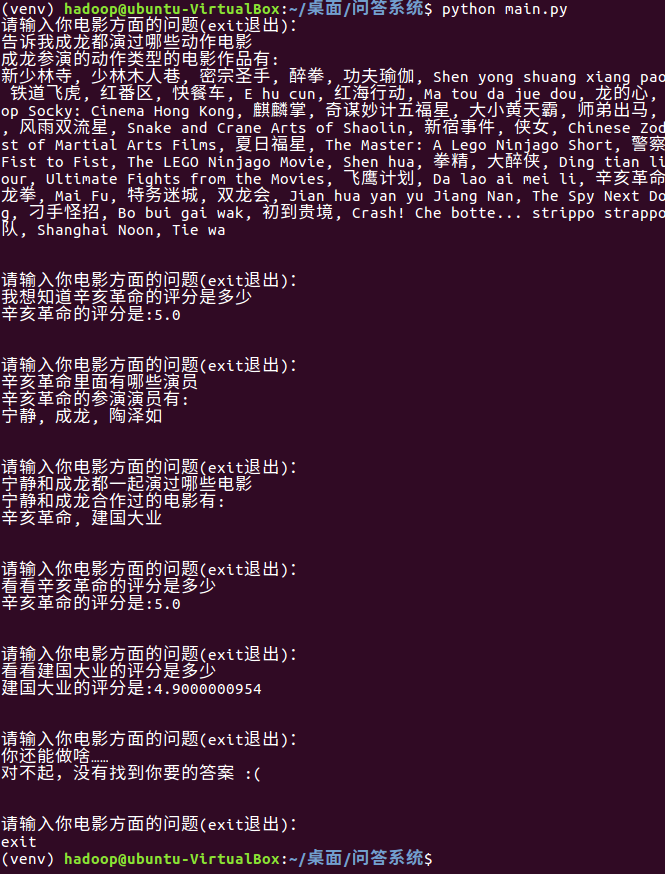
交互式效果