K-Means 聚类
聚类属于无监督学习的一种。聚类和分类是不同的,分类是已知有哪些类别,需要将数据划分到这些类别中去;聚类是不知道有哪些类别,由算法将数据划分成指定的类别数。
聚类算法有很多,其中很基础的就是 K-Means(K 均值)聚类算法
K-Means 的基本步骤:
- 随机初始化聚类中心
- 每个样本计算到各个聚类中心的距离,每个样本和自身距离最近的聚类中心归为一类
- 对划分的每一类重新计算聚类中心
- 重复二、三步直至聚类中心不变
初始化方法
基础的 K-Means 初始化聚类中心是随机的,也就是说,从所有样本点中随机取 k 个样本点(假如希望聚k类)作为聚类中心。这样,初始的聚类中心可以保证一定在数据集的范围之内。
K-Means 是对初始的聚类中心很敏感的,随机选择出来的点可能相互之间距离会非常近,这样第一次聚类的效果就会不太好。针对这一问题,有人提出了 kmeans++ 方法进行初始化,这一方法可以使初始化的聚类中心相互之间尽可能离得远一些,提高聚类的效果。但 kmeans++ 不在本文讨论的范畴。
距离计算
假设有三个数据点: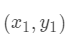
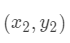
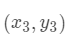
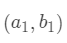
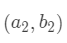
那么计算第一个数据点到第一个聚类中心距离的式子就是
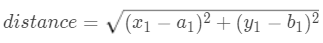
以此类推。
聚类中心更新
假设第一类有两个数据点:
那么计算第一类中新的聚类中心 x 坐标的式子就是
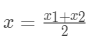
下面用构建一个简单数据集来演示聚类过程
首先随机构造一个可以被分为两类的数据集
1# 构建数据集
2n_samples = 50 # 数据集大小
3
4import random
5cluster_a = [(random.randint(10,500), random.randint(10, 80)) for i in range(n_samples)] # a 类数据
6cluster_b = [(random.randint(520,1020), random.randint(50, 120)) for i in range(n_samples)] # b 类数据
7
8# 可视化初始数据
9import matplotlib.pyplot as plt
10plt.figure(figsize=(10, 2.5)) # 设置画布大小
11plt.subplot("111")
12X = cluster_a + cluster_b
13plt.scatter([x[0] for x in X], [x[1] for x in X], c="b", s=10)
1<matplotlib.collections.PathCollection at 0x1b6e0c1fe10>

构建好了数据集,接下来先用现成的工具包看一下聚类的效果
sklearn.cluster 封装的是聚类算法,其中自然包括 K-Means 算法。通过现成的封装代码看一下聚类的效果,有一个直观的感受。
1# 使用 sklearn.cluster 工具完成聚类 ##
2from sklearn.cluster import KMeans
3kmeans = KMeans(n_clusters=2, init="k-means++") # "random" 表示随机初始化聚类中心,"k-means++" 是改进过的初始化方法
4result = kmeans.fit_predict(X) # 训练聚类模型并完成聚类
5centers = kmeans.cluster_centers_ # 类别中心点(有的出处称其为质心)
6
7# 可视化聚类结果
8colors = ["red", "green"]
9plt.figure(figsize=(10, 2.5)) # 设置画布大小
10plt.subplot("111")
11plt.scatter([x[0] for x in X], [x[1] for x in X], c=[colors[x] for x in result], s=10)
12plt.scatter([x[0] for x in centers], [x[1] for x in centers], c=colors, marker="X", s=100)
1<matplotlib.collections.PathCollection at 0x1b6e0931da0>

接下来,就根据 K-Means 的原理,动手实现一下算法
1## 根据聚类原理实现聚类算法 ##
1# 代码一
2# 质心初始化为数据集中的任两个数据点
3# 只绘制最后结果
4
5# [centers_a, centers_b] = [random.choice(X) for x in range(2)] # 初始化质心,此处在数据集中随机选两个质心
6[centers_a, centers_b] = [(random.randint(10,1020), random.randint(10, 120)) for x in range(2)] # 初始化质心,此处在一定范围内随机选两个点
7
8max_iteration = 300 # 最大迭代次数
9clusters = [] # 保存聚类结果
10for i in range(max_iteration):
11 distance_a = [(x[0]-centers_a[0])**2+(x[1]-centers_a[1])**2 for x in X] # 计算各点到质心 a 的距离
12 distance_b = [(x[0]-centers_b[0])**2+(x[1]-centers_b[1])**2 for x in X] # 计算各点到质心 b 的距离
13 clusters = [0 if dis[0] < dis[1] else 1 for dis in zip(distance_a, distance_b)] # 根据距离归类,距离 a 近为 0,否则为 1
14 # 根据归类结果划分数据
15 predict_a = []
16 predict_b = []
17 for index, x in enumerate(X):
18 if clusters[index] == 0:
19 predict_a.append(x)
20 else:
21 predict_b.append(x)
22 # 重新计算质心
23 temp_a = (sum([x[0] for x in predict_a])/len(predict_a), sum([x[1] for x in predict_a])/len(predict_a))
24 temp_b = (sum([x[0] for x in predict_b])/len(predict_b), sum([x[1] for x in predict_b])/len(predict_b))
25 if temp_a == centers_a and temp_b == centers_b: # 质心不再变化
26 print("End at iteration:", i)
27 break
28 else:
29 centers_a = temp_a
30 centers_b = temp_b
31
32# 可视化聚类结果
33plt.figure(figsize=(10, 2.5)) # 设置画布大小
34colors = ["red", "green"]
35centers = [centers_a, centers_b]
36plt.subplot("111")
37plt.scatter([x[0] for x in X], [x[1] for x in X], c=[colors[x] for x in clusters], s=10)
38plt.scatter([x[0] for x in centers], [x[1] for x in centers], c=colors, marker="X", s=100)
1End at iteration: 3
2<matplotlib.collections.PathCollection at 0x1b6df151908>
上面的代码只展示了最后结果,下面是把每一次迭代后的效果都展示出来,可以清晰地看到聚类的整个过程。
1# 代码二
2# 质心初始化为数据集中的任两个数据点
3# 展示每一步结果
4
5[centers_a, centers_b] = [random.choice(X) for x in range(2)] # 初始化质心,此处在数据集中随机选两个质心
6# [centers_a, centers_b] = [(random.randint(10,1020), random.randint(10, 120)) for x in range(2)] # 初始化质心,此处在一定范围内随机选两个点
7
8
9max_iteration = 30 # 最大迭代次数
10clusters = [] # 保存聚类结果
11plt.figure(figsize=(10, max_iteration*3)) # 设置画布大小
12colors = ["red", "green"]
13
14# 绘制初始情况
15plt.subplot(max_iteration, 1, 1)
16centers = [centers_a, centers_b]
17plt.scatter([x[0] for x in X], [x[1] for x in X], c='b', s=10)
18plt.scatter([x[0] for x in centers], [x[1] for x in centers], c=colors, marker="X", s=100)
19
20for i in range(max_iteration):
21 distance_a = [(x[0]-centers_a[0])**2+(x[1]-centers_a[1])**2 for x in X] # 计算各点到质心 a 的距离
22 distance_b = [(x[0]-centers_b[0])**2+(x[1]-centers_b[1])**2 for x in X] # 计算各点到质心 b 的距离
23 clusters = [0 if dis[0] < dis[1] else 1 for dis in zip(distance_a, distance_b)] # 根据距离归类,距离 a 近为 0,否则为 1
24 # 根据归类结果划分数据
25 predict_a = []
26 predict_b = []
27 for index, x in enumerate(X):
28 if clusters[index] == 0:
29 predict_a.append(x)
30 else:
31 predict_b.append(x)
32 # 重新计算质心
33 if len(predict_a) != 0: # 在一定范围内随机取点时,可能出现全部被划分为同一类的情况,此时另一类为空,需保证下式除数不为零
34 temp_a = (sum([x[0] for x in predict_a])/len(predict_a), sum([x[1] for x in predict_a])/len(predict_a))
35 if len(predict_b) != 0:
36 temp_b = (sum([x[0] for x in predict_b])/len(predict_b), sum([x[1] for x in predict_b])/len(predict_b))
37
38 if temp_a == centers_a and temp_b == centers_b: # 质心不再变化
39 print("End at iteration:", i)
40 break
41 else:
42 centers_a = temp_a
43 centers_b = temp_b
44
45 # 可视化每次的聚类结果
46 centers = [centers_a, centers_b]
47 plt.subplot(max_iteration, 1, i+2)
48 plt.scatter([x[0] for x in X], [x[1] for x in X], c=[colors[x] for x in clusters], s=10)
49 plt.scatter([x[0] for x in centers], [x[1] for x in centers], c=colors, marker="X", s=100)
1End at iteration: 4

上面代码使用的初始化方法都是随机地在数据集中选取两个点作为聚类中心,下面的代码演示的是在一定范围内选取两个随机点作为聚类中心,也就是说聚类中心不在数据集当中产生。自然,这种方法的效果是没有上面的好的,但不妨尝试一下。
1# 代码三
2# 质心初始化为一定范围内的任两个点
3# 展示每一步结果
4
5# [centers_a, centers_b] = [random.choice(X) for x in range(2)] # 初始化质心,此处在数据集中随机选两个质心
6[centers_a, centers_b] = [(random.randint(0,2000), random.randint(0, 300)) for x in range(2)] # 初始化质心,此处在一定范围内随机选两个点
7
8max_iteration = 30 # 最大迭代次数
9clusters = [] # 保存聚类结果
10plt.figure(figsize=(10, max_iteration*3)) # 设置画布大小
11colors = ["red", "green"]
12
13# 绘制初始情况
14plt.subplot(max_iteration, 1, 1)
15centers = [centers_a, centers_b]
16plt.scatter([x[0] for x in X], [x[1] for x in X], c='b', s=10)
17plt.scatter([x[0] for x in centers], [x[1] for x in centers], c=colors, marker="X", s=100)
18
19for i in range(max_iteration):
20 distance_a = [(x[0]-centers_a[0])**2+(x[1]-centers_a[1])**2 for x in X] # 计算各点到质心 a 的距离
21 distance_b = [(x[0]-centers_b[0])**2+(x[1]-centers_b[1])**2 for x in X] # 计算各点到质心 b 的距离
22 clusters = [0 if dis[0] < dis[1] else 1 for dis in zip(distance_a, distance_b)] # 根据距离归类,距离 a 近为 0,否则为 1
23 # 根据归类结果划分数据
24 predict_a = []
25 predict_b = []
26 for index, x in enumerate(X):
27 if clusters[index] == 0:
28 predict_a.append(x)
29 else:
30 predict_b.append(x)
31 # 重新计算质心
32 if len(predict_a) != 0: # 在一定范围内随机取点时,可能出现全部被划分为同一类的情况,此时另一类为空,需保证下式除数不为零
33 temp_a = (sum([x[0] for x in predict_a])/len(predict_a), sum([x[1] for x in predict_a])/len(predict_a))
34 if len(predict_b) != 0:
35 temp_b = (sum([x[0] for x in predict_b])/len(predict_b), sum([x[1] for x in predict_b])/len(predict_b))
36
37 if temp_a == centers_a and temp_b == centers_b: # 质心不再变化
38 print("End at iteration:", i)
39 break
40 else:
41 centers_a = temp_a
42 centers_b = temp_b
43
44 # 可视化每次的聚类结果
45 centers = [centers_a, centers_b]
46 plt.subplot(max_iteration, 1, i+2)
47 plt.scatter([x[0] for x in X], [x[1] for x in X], c=[colors[x] for x in clusters], s=10)
48 plt.scatter([x[0] for x in centers], [x[1] for x in centers], c=colors, marker="X", s=100)
1End at iteration: 4

以上是关于基本 K-Means 算法的全部内容,本文代码已上传至 GitHub
