简记:Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers
写在前面:这是一篇做自然图像弱监督语义分割的论文,利用图像级的类别标签来实现像素级的语义分割,文中部分做法和论文 IRN中的做法类似。这篇论文采用的骨干网络为 Mix Transformer (MiT) 。论文收录于 CVPR2022 ,论文地址为:https://rulixiang.github.io/afa/,代码地址为:https://github.com/rulixiang/afa
创新点描述
- 提出了端到端的、只利用图像级标签的、基于Transformer的 弱监督语义分割框架
- 提出了 Affinity from Attention (AFA) 模块,用于从Transformer的多头自注意力(MHSA)中学得语义亲和度(semantic affinity)的信息,用于 propagate (传播/扩散/生长)伪标签(pseudo label)
- 提出了 Pixel-Adaptive Refinement (PAR) 模块,用于 incorporate (合并/混合)图像的颜色信息(RGB)和空间信息(像素坐标),用于优化伪标签
整体结构
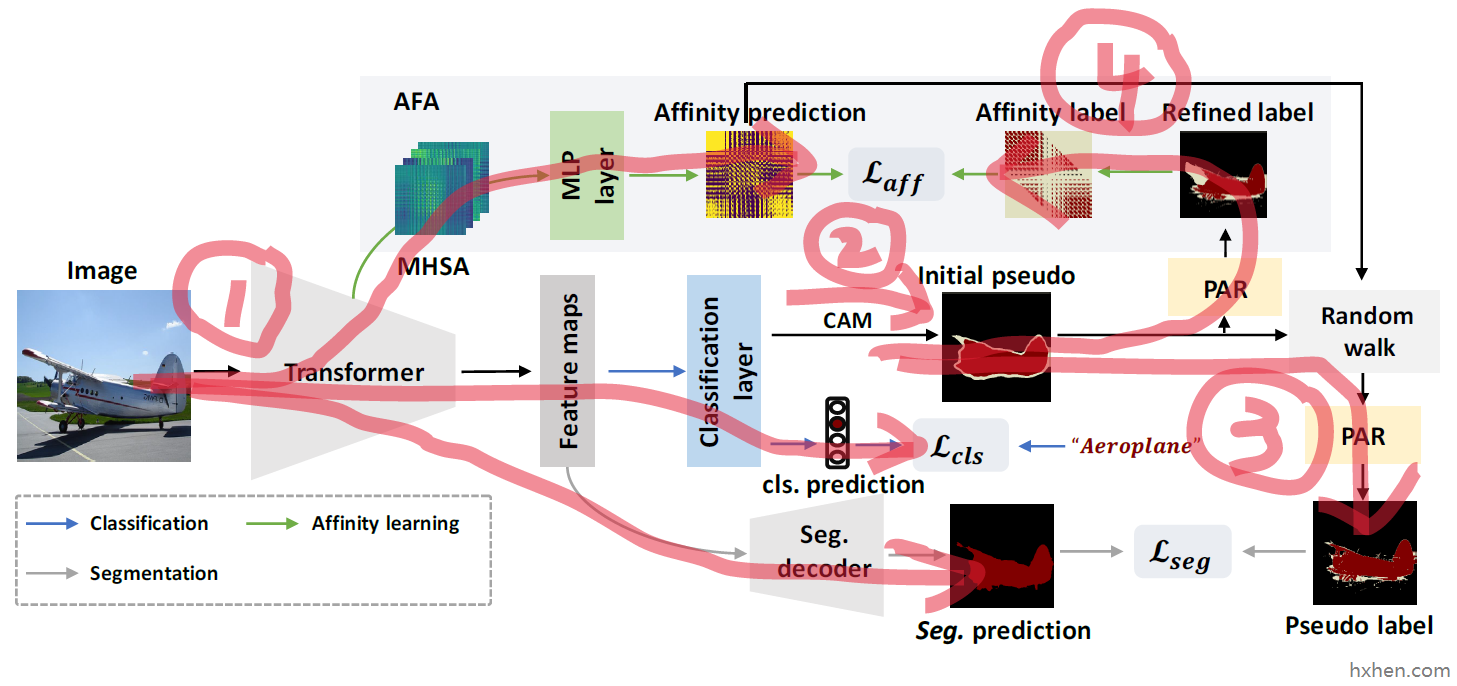
以我目前的理解,整个模型可以分成4条路径:
- 路径一是Transformer输出三个数据:预测的类别 classification prediction,预测的分割结果 segmentation prediction,预测的亲和度矩阵 affinity prediction。其中类别预测结果是直接使用已有的图像级标签来进行监督的。分割结果和亲和度矩阵的监督信息需要通过后面三个部分获得。
- 路径二是生成类激活图(Class Activation Map,CAM),并基于CAM生成初始伪标签。
- 路径三是对初始伪标签进行优化,主要用到 random walker 算法和 PAR 模块,优化后得到最终伪标签,用于监督分割结果的生成。
- 路径四是先对初始伪标签进行优化,主要用到 PAR 模块,使用优化后的伪标签生成亲和度矩阵的标签,用于监督亲和度矩阵的生成。
下面分别记录对四条路径的理解。
路径一:Transformer编码器的三个输出结果
编码器输出类别的预测结果、分割的预测结果、亲和度矩阵的预测结果。主要创新的是亲和度矩阵的预测输出。
亲和度矩阵的生成
对于Transformer中的多头注意力,可以记为 token 尺度下的尺寸,或者说 patch 尺度下的尺寸;patch 的数量; head 的数量)。如文章中所说:多头注意力可以看作是有向图,但图像区域之间的亲和度应该是相互对称的。所以这里采用了原注意力矩阵和其自身的转置相加的处理方式来获得对称的注意力矩阵,记为 MLP layer (从程序上看图中的 MLP layer 是单层卷积?),将原本的 公式3 ):
其中
路径二:CAM的生成、初始伪标签的生成
路径二是生成CAM,以及利用CAM生成初始的伪标签(pseudo label / pseudo mask)。
CAM的生成
Transformer作为编码器,每幅输入的图像都会对应一组它输出的特征图 Classification layer 之后得到
值得留意的是:这里的CAM并非简单地输入一张原图,得到对应的CAM输出就结束了。从程序中看,最终的CAM是多尺度融合的结果,即:每张图像构建一组经过缩放的不同尺寸的图像序列,然后获取这些不同尺寸图像的CAM图,经过缩放统一到相同尺寸并累加,获得多个尺度融合后的CAM图。
整个过程用公式表达为(对应原文 公式2 ):
其中
初始伪标签的生成
预先定义了范围为 0~1 的两个超参数
- 低于
0,表示可信背景区域 - 高于
argmax获得各像素位置的类别。如:任务有4个类别,则这部分区域的取值范围为 - 介于两者之间的区域置为
255,表示不确定区域,不予处理
整个过程用公式表达为(对应原文 公式4):
其中
路径三:最终伪标签的生成
路径三是先用 random walk 算法对伪标签进行扩散传播(propagation),然后利用文章提出的PAR模块对伪标签进一步优化。
伪标签的扩散传播
使用随机游走算法(Random Walk)对初始伪标签进行扩散传播。先对亲和度矩阵
整个过程用公式表达为(对应原文 公式6 和 公式7):
其中,flatten 或者 reshape 操作,将
PAR模块对伪标签的优化
通过阅读文章提供的程序,按照我的理解,这个PAR模块是一个变相的均值滤波的过程。普通的均值滤波是直接取8邻域求均值,PAR模块里面的邻域范围更大,而且巧妙地用膨胀卷积实现了取邻域元素的过程。PAR的这一实现方式能够利用GPU加速,效率高。同时也能注意到,整个PAR模块并不涉及可训练的参数,唯一可能涉及的卷积层是用的固定卷积核。从变相均值滤波的思想上看,这个过程也确实不需要可训练的参数。
下面记录一下如何利用卷积来抽取邻域元素:

如示意图所示,这里构造了一个8通道的卷积核,从第1个通道到第8个通道,依次将第1到第8个位置置1,其余位置置0,用此卷积核对图像做卷积操作,就能达到取8邻域元素的效果。搭配已经封装好的膨胀卷积操作,就能取得范围更大的邻域元素。
路径四:亲和度矩阵标签的生成
路径一预测的亲和度矩阵缺少对应的标签来监督这个过程,路径四的目的就是生成对应的标签。具体来看,这里是取 random walk 之前的初始伪标签,用PAR模块做优化(这里仍将优化后的伪标签记为
伪标签转亲和度矩阵标签的过程和 IRNet 中的一处做法类似。
如果
- 如果
- 如果
- 如果
如果
此外,邻域外的关系均置为 255,且
按照上述规则就能得到亲和度矩阵的标签
损失函数
整个模型包含四项损失:“类别预测”对应的多标签分类损失 Multi-label Soft Margin Loss Cross-entropy Loss Affinity Loss Dense Energy Loss
完整的损失函数用公式表示如下:
其中各
下面记录一下亲和度损失的计算:
亲和度损失的公式如下:
(按照我的理解,文章中的公式应该是将加号代表的positive项和减号代表的negative项写反了,所以上面式子的加减号上标和原文刚好相反,如理解不当望指出。)
其中,MSE 的变体,即忽略了不确定区域的MSE。positive位置对的标签为1,negative位置对的标签为0,不确定区域不计算损失。