2022.4.29 更新:论文作者已经公开了源码,快去学习~ 地址:https://github.com/jinsuyoo/act
(至于我自己复现的程序就别抱期待了,复现的程序在分类数据集上效果不好,而且没有做预训练,拟合速度很慢。总之就是太菜了,没能复现好,能力还有待提升 _(:з」∠)_ 。我也去看源码学习去了)
这篇文章提出了一个应对图像超分辨问题(super-resolution,SR)的模型 ACT ,文章于 2022年3月 提交在 arxiv 上,文章链接为:https://arxiv.org/abs/2203.07682,这篇文章对应的程序并未公开。我对其做了复现,由于我目前主要做分类问题,所以相比原结构会有所改动,复现的程序经过实验验证后会适时公开。
简要介绍
这篇文章提到:
- CNN 结构很难捕捉图像中长距离的依赖关系,因为卷积操作都是针对局部像素的。相反,Transformer 的结构很适合捕捉长距离依赖关系 [1]
- CNN 结构很难重建图像的弱纹理细节。文章的实验部分举了实际例子来说明 Transformer 更加擅长重建图像的弱纹理细节 [2]
这篇文章的主要贡献:
- 介绍了一个混合了 CNN 和 ViT 结构的图像超分辨方法 ACT。
- 提出了跨尺度块注意力(cross-scale token attention,CSTA)模块,用于有效利用多尺度的块表征信息(multi-scale token representations)。
- 进行了广泛实验,证明了 ACT 模型在众多图像超分辨的实验基准中都具有优势。
模型结构
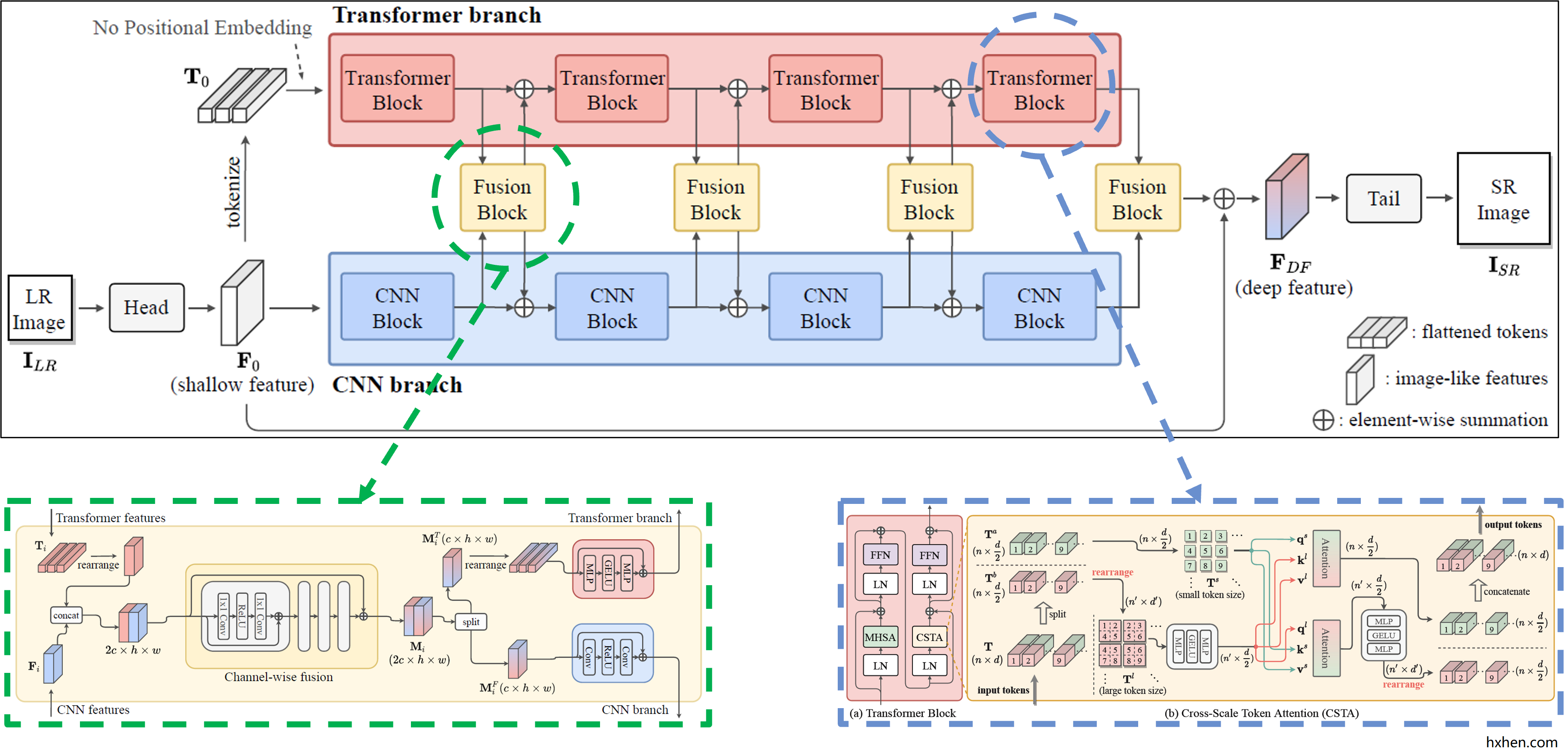
整个模型整体由 Head,CNN branch,Transformer branch,Fusion Block,Tail 五个部分组成。其中,Head 用于提取图像的浅层特征;CNN branch 由多个残差卷积块(CNN Block)组成,用于提取 CNN 特征;Transformer branch 由多个 Transformer 自注意力模块(Transformer Block)组成,用于提取 Transformer 特征;Fusion Block 用于融合各层的 CNN 特征和 Transformer 特征;Tail 在本文中用于增加图像分辨率,重建图像,属于 decoder 部分。Head 和 Tail 与剩余组件互不干扰,可以很方便地替换成其他结构。
Head 和 Tail
这两部分的描述较为简单,Head 部分由两个残差卷积块组成,Tail 部分由 PixelShuffle 操作和卷积层组成(PixelShuffle 操作是一种特征图上采样的方式,其用途和反卷积、线性插值等方法相同)。公式表达为:
其中,
CNN branch
文章对于 CNN 分支的描述也比较简单,整个 CNN 分支由4个 CNN Block 连接而成,每个 CNN Block 由12个残差通道注意力模块(residual channel attention block,RCAB)堆叠而成。RCAB 模块是在 RCAN 这篇文章中提出来的,有对应的公开程序 [3] 。
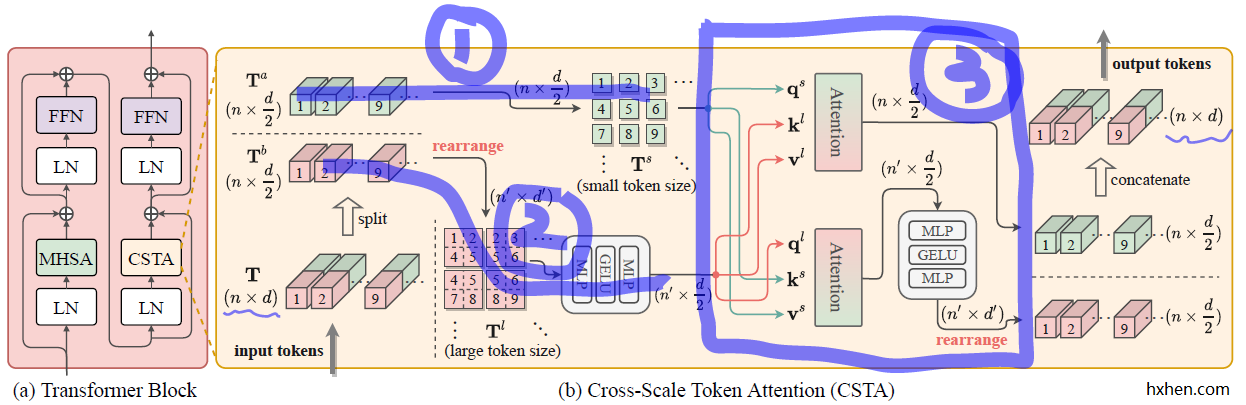
Transformer Block (蓝色框)
将这篇文章的 Transformer Block 和 ViT 中原始的 Transformer Block 相对比,能够发现其不同之处在于:这里将两个原始block连接在一起作为一个整体,然后将第二个block的多头自注意力模块(MHSA)换成了这篇文章提出的跨尺度块注意力模块(CSTA)。
和原始 Transformer Block 相同的结构不再赘述,这里记录下 CSTA 模块的结构。
CSTA 模块
这个 CSTA 模块从论文提供的实现细节来看,是计算
步骤2:先将
这样便得到了两组 Q、K、V 用于计算注意力,即:
步骤3:根据自注意力的计算公式,
如此一来,两个不同token尺寸的特征之间便完成了注意力的计算和特征的加权,这也就是这个模块跨尺度注意力的含义。两个加权后的特征均为
Fusion Block (绿色框)
Transformer 特征和 CNN 特征的融合模块结构更为简单易懂,可以分成特征拼接(步骤1)、特征融合(步骤2)、特征拆分(步骤3)三个部分。整个融合模块是两进两出的状态。
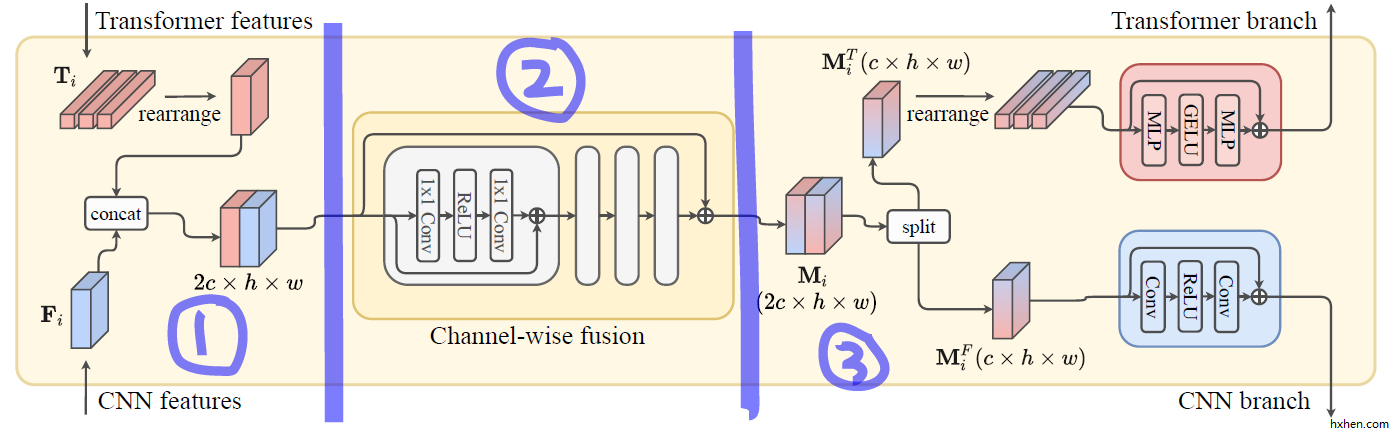
步骤1: Transformer 的特征格式是
步骤2: 融合部分是用的
步骤3: 融合后的特征图是
值得一提的是, 最后一个融合模块是两进一出的,也就是步骤3不需要做拆分了,而是直接让
还有什么有意思的?
我觉得在 Head 之后 Transformer 分支之前的 tokenize 步骤值得记录下。这里的分块步骤和上面提到多次的重组步骤都是采用的相同的方法,可以用 torch 的 Fold 和 Unfold 方法实现,这在文章附录的伪代码里能看到。
这个步骤会联想到 Transformer 的分块步骤,虽然功能都是分块,但实现方式是不同的。Transformer 的分块操作是利用卷积层实现的,这里的 tokenize 由于已经有现成的特征图了,也就不需要卷积操作,直接重组即可。
文中提及的部分文献
[1] An image is worth 16×16 words: Transformers for image recognition at scale(ICLR 2021)
[2] Pre-Trained Image Processing Transformer(CVPR 2021)
[3] Image Super-Resolution Using Very Deep Residual Channel Attention Networks(ECCV 2018) (源码:https://github.com/yulunzhang/RCAN)
什么时候能分享一下你的代码啊?感谢感谢
我刚发现作者发布源码了,地址:https://github.com/jinsuyoo/act
还是看作者的源码吧,我的没复现好,太菜了……
哇,太谢谢了