这篇文章是针对 ViT 的一个改进,测试基准为 ImageNet 分类。改进之处可以概况为:在 Transformer 主干之前增加了一个 Tokens-to-Token(T2T) 模块,并将 Transformer 主干以「深而窄」的形式重新设计。
程序地址为:https://github.com/yitu-opensource/T2T-ViT
引言
文章在引言部分抛出来一个观点:Transformer 虽然已在很多视觉任务上都能取得不错的结果,但在中等大小的数据集上从零训练时,其效果仍然要弱于同等体量的 CNN (题外话:对范围做了限定,很严谨 )
随后文中对这一问题产生的原因提出了自己的看法:
- ViT 简单直接的切片处理让 Transformer 难以提取图像边缘、线条等局部特征
- ViT 主干结构所提取的特征在多样性和有效性上还存在不足
并提供了可视化的特征图作为佐证。图中的绿色框指包含了图像边缘信息的特征图,红色框指空白的特征图。第二排的 ViT 没有绿框有红框便是对上面两个看法的佐证。

整体结构
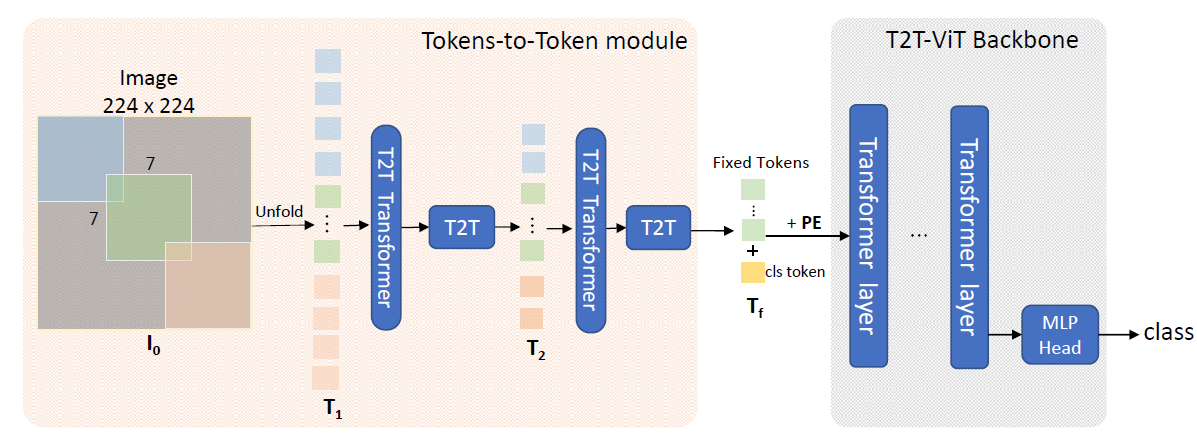
整个模型分为 Tokens-to-Token(T2T) 模块和 Transformer 主干。可以看到,整个 T2T 的作用可以理解为生成了更加优质的 token,对比于 ViT 用的 token 是直接通过一个卷积层(步长与卷积核尺寸相同)得到的。Transformer 主干是通过实验确定下来的 「深而窄」的一个 Transformer 结构。
首先图像被可重叠地拆分成一个个的 patch (
由于每个 patch 的特征维度增加了,为了避免整个模型计算量过大,所以 T2T 模块中用到的 Transformer Layer 都将特征维度调的更小了(32或64)。
之后各个 patch 再经过一个 Transformer Layer 和 T2T Block 即成为 T2T 模块的输出,各个 patch 特征即为各个 token。
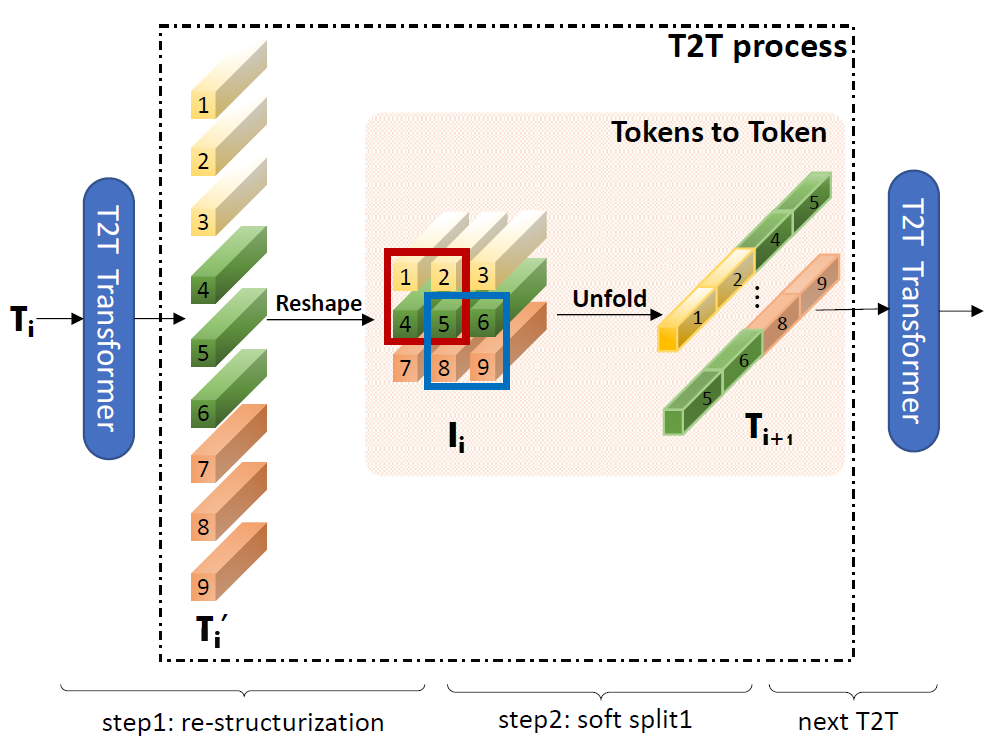
T2T Block
这里单独把一个 T2T 模块单独拎出来看,能看到将
Transformer 主干
主干部分探索了 5 种 CNN 结构应用到 Transformer 上的效果:
- DenseNet 的密集连接
- Wide-ResNets 的 「深而窄」结构和「浅而宽」结构
- SENet 中的通道注意力模块
- ResNeXt 中 head 数量更多的多头注意力层(multi-head attention layer)
- GhostNet 中的 Ghost 模块
然后通过实验探索上述改动的效果,从实验结果发现如下规律:
- 使用深而窄的结构(降低特征维度,增加模型层数)能够减少模型参数并提高效果。
- 使用通道注意力也会有帮助,但不如第1点改成深而窄的结构帮助大。
实验结果
本文是强调从零开始训练 ImageNet,实验结果表明,本文改进后的模型比体量相当的 ViT、DeiT 高出了 1% 到 2% 的 top-1 准确率。实验结果里还有上述各个 CNN 结构移植到 Transformer 上的详细准确率变化,可以提供一定的参考。