这是一篇收录于 CVPR 2022 的文章,它提供了一种图文(多模态)融合的方案,针对的是多模态数据的分类任务。论文链接为:https://openaccess.thecvf.com/content/CVPR2022/html/Liang_Expanding_Large_Pre-Trained_Unimodal_Models_With_Multimodal_Information_Injection_for_CVPR_2022_paper.html ,暂无对应公开代码。

主要特点:
- 提出的 MI2P 模块(Multimodal Information Injection Plug-in),能直接用于已有的单模态大规模预训练模型
- 能对已有的大规模单模态模型进行扩展,即,可以在微调过程中将文本数据加入到CNN模型的训练,或者将图像数据加入到 Bert 模型的训练
回顾已有的多模态融合方案
| 方案一 | 方案二 |
|---|---|
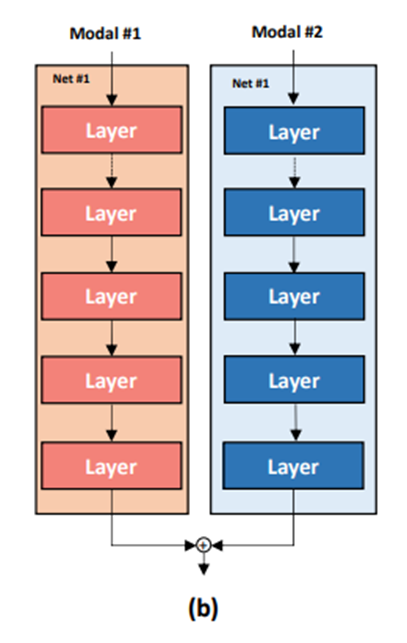 | 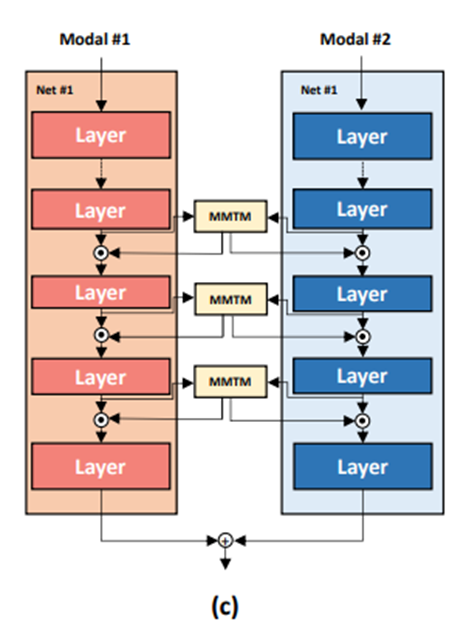 |
(此处两幅示意图取自论文:https://openaccess.thecvf.com/content_CVPR_2020/html/Joze_MMTM_Multimodal_Transfer_Module_for_CNN_Fusion_CVPR_2020_paper.html)
方案一是两个分支独立提取各自模态的信息,两个模态的信息在模型末端进行融合。在这种方案下,同一模态内的信息能得到充分的挖掘,但模态间的信息交互会显得仓促。方案二是两个分支的信息在中部进行多次融合。在这种方案下,模态间的信息能得到充分交互,但提取各模态内部信息的过程可能受到干扰。
这时来看这篇提出 MI2P 模块的方法:
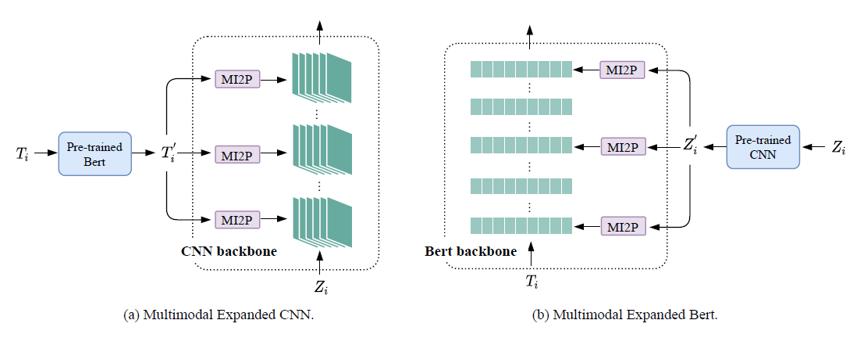
它既保持了预训练模型原有模态数据的特征提取流程,又在模型的各个层融入了外来模态的特征,所以可以看成在上述两类方案之间取得了平衡。值得注意的是,外来模态的特征都是直接加载预训练权重获得的,左图的 Bert 和右图的 CNN 都只作为外来模态的特征提取器,不参与微调过程的训练。
文章中用 “heterogeneity”(异质性) 这个单词来形容 图、文 这两种数据之间的差异,正是考虑到这一差异的存在,才没有直接把特征提取器提取的特征直接加入到预训练模型主干的计算过程中。这篇文章提出的 MI2P 模块就是为了衔接和转换这两种不同模态的数据。
MI2P 模块的处理流程
我们知道 CNN 的特征图格式一般是 torch 下的 fold()、unfold()、reshape 等方法,都能让它们在维度上表现得一致(再不济也还能插值)。但在设计模型时还是需要考虑处理过程的可解释性、合理性,这篇文章则是通过分析 CNN 特征图和文本数据之间的对应关系,来让 MI2P 的处理流程更加合理。
对于 CNN 提取的特征图来说,通常表现为不同通道(channel)的特征图会关注不同的图像区域。

(图片取自:https://www.kaggle.com/arpitjain007/guide-to-visualize-filters-and-feature-maps-in-cnn)
而对于文本来说,不同的单词就对应着不同的区域。比如对于下面这幅图像,它是由 DALL-E mini 模型根据英文描述 “An elephant is drinking from the stream with its long nose” 生成的,如果让 CNN 来提取这幅图像的特征,可能某个通道的特征图关注的是象鼻子(nose),有的通道的特征图关注的是溪流(stream)。从这个角度来说,CNN 的通道特征和文本的单词特征之间,是存在一定的对应关系的。

(图片由 DALL-E mini 模型根据英文描述 “An elephant is drinking from the stream with its long nose” 生成 ,https://huggingface.co/spaces/dalle-mini/dalle-mini )
所以,本文方法将单个通道的图像特征视为一个 token,将一个个单词的特征视为一个 token,采用注意力加权的方式进行特征的转换。
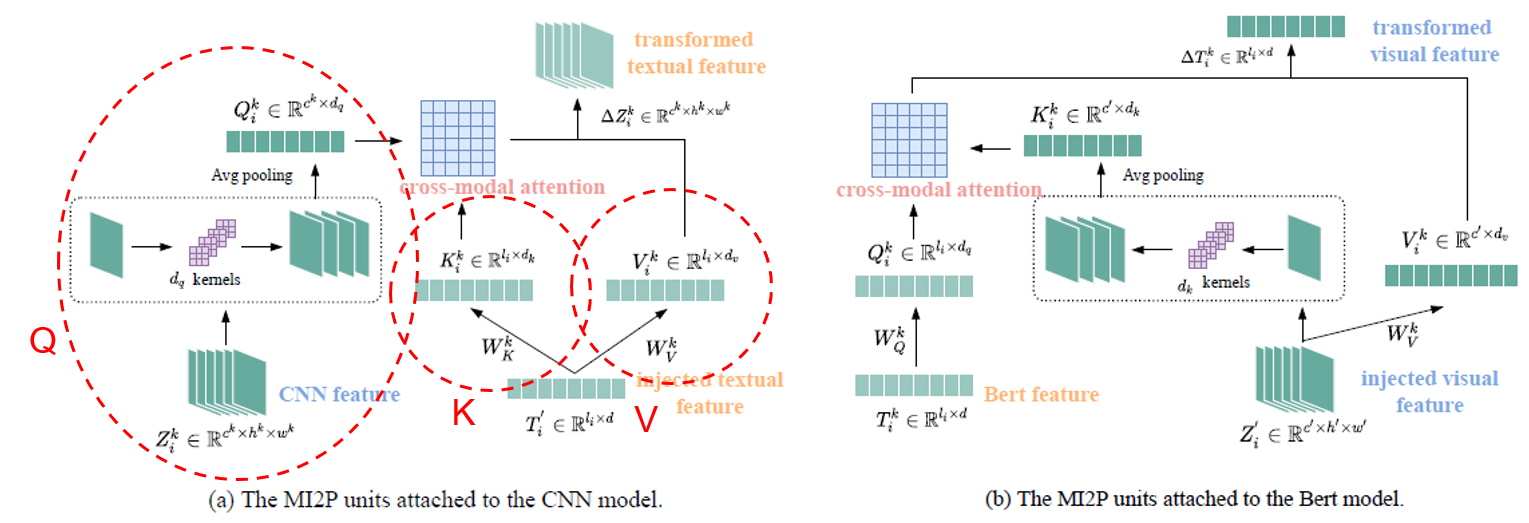
上图左侧是给图像特征融入文本特征的过程,右侧是给文本特征融入图像特征的过程。
具体的转换过程其实是和 Transformer 的注意力计算过程是一致的,即图像数据先从
但对于这个图像数据转换的过程我还是有些不解的地方。右侧给文本特征融入图像特征的过程中涉及两种图像数据的形式转换:由图像数据
这个卷积加全局池化进行图像形式转换的过程也有一个值得注意的点,即,这里是将各个通道的二维特征图
拓展模型的进一步组合
经过拓展,CNN + MI2P 和 Bert + MI2P 都具备了融合图文信息的能力,也都能独立地完成分类任务。在此基础上,这篇文章进一步对这两个拓展后的模型进行了组合,最终获得了比单个拓展模型更优的结果。文章通过实验比较了下面三种组合方式:
- 直接融合最后输出的分值
- 融合最后输出的特征
- 使用注意力加权的方式获得最终的特征
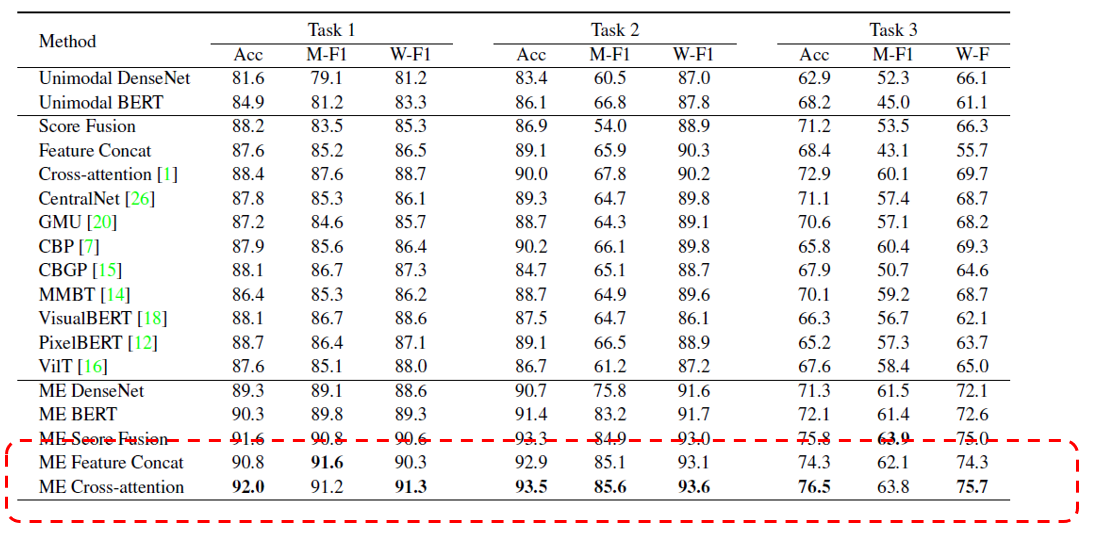
从实验结果上看,第 3 种组合方式效果最佳。
附上在 CrisisMMD 数据集上的实验结果:
以及在 Food101 和 MM-IMDB 数据集上的实验结果:
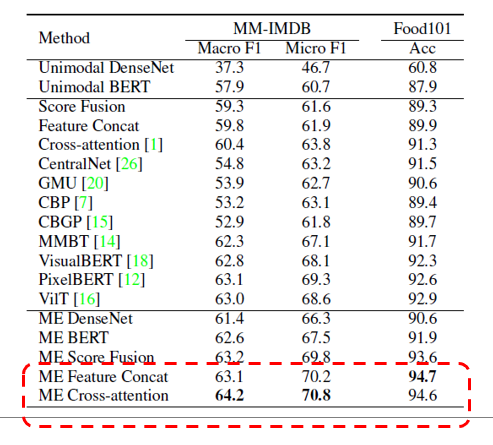
(注:文中未标注来源的图片均来自论文 “Expanding Large Pre-trained Unimodal Models with Multimodal Information Injection for Image-Text Multimodal Classification”)