这是一篇收录于 NeurIPS 2021 的论文,原版标题为 “DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification”,只涉及 ViT 结构。论文作者后续将相同的思想拓展到了 ConvNeXt 和 Swin Transformer 这两种结构上,于是有了目前这一版论文 “Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks”
论文提出的 DynamicViT 能够对 token 进行动态稀疏化,原理是根据图像特征动态生成 decision mask,并用它来消除 Vision Transformer 中的冗余 token。相比于各种 Vision Transformer 模型,DynamicViT 可减少30%以上的计算量(FLOPs),提高40%以上的吞吐量(FPS),同时保证准确率损失不到 0.5%
论文:https://arxiv.org/abs/2207.01580v1
程序:https://github.com/raoyongming/DynamicViT
这篇记录主要围绕两个问题:
- 如何根据图像特征生成 decision mask
- 如何用 decision mask 消除冗余特征
论文涉及两类主干结构,一是特征图尺寸维持不变的 ViT 结构,二是特征图逐级减小的 ConvNeXt 和 Swin Transformer 结构。两类结构在生成 decision mask 的实现上基本相同,但在消除冗余特征的方式上存在较大区别。由于对 ConvNeXt 的处理方式和 Swin Transformer 类似,因此没有单独记录。
1. 生成 decision mask

decision mask 是一组尺寸与特征图相同的二值矩阵
1.1 对于 ViT 结构来说
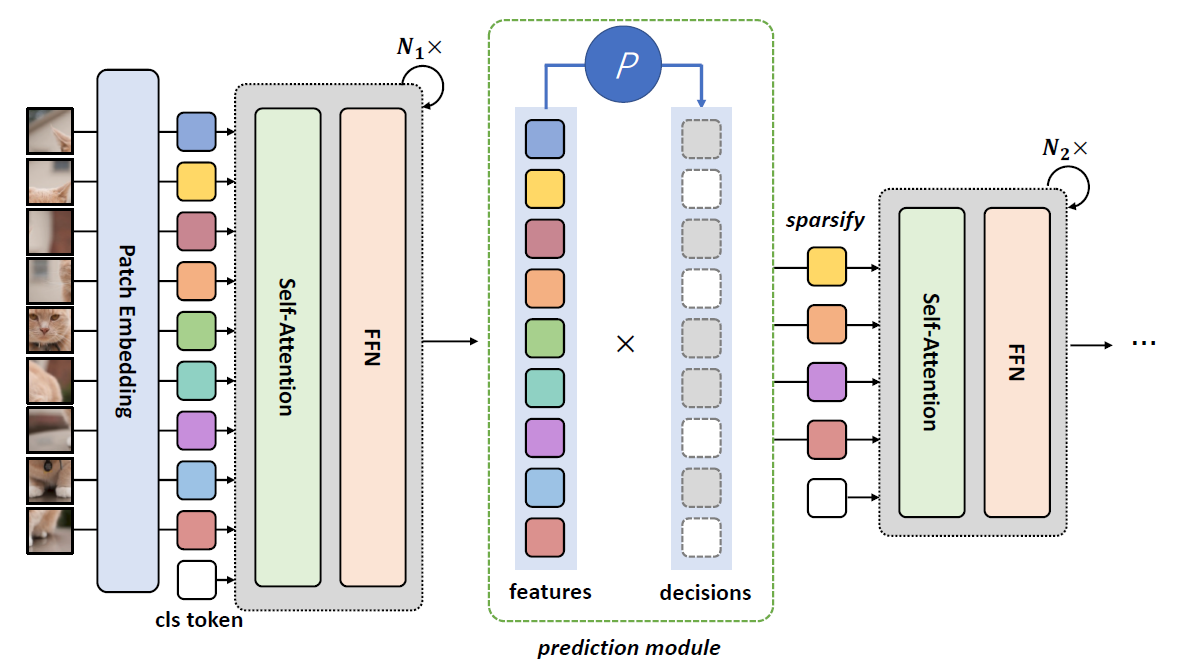
模型维护一个全局的 precision mask(用
decision score 在数值上是连续的,为了得到二值化的 decision mask,用 Gumbel-Softmax 技巧从 decision score 采样得到当前的 decision mask(用
为什么要用 Gumbel-Softmax 技巧采样获得 decision mask,而不直接 argsort 或者用 choice 获得 decision mask? 因为 argsort,argmax 和 choice 采样方法都是不可微的,这里引入的 decision mask 是可学习参数,是需要在训练期间通过梯度反向传播来不断更新的,因此需要通过 Gumbel-Softmax 技巧来保证采样过程的可微,torch.nn.functions 中有这一技巧的官方实现。
1.2 对于 Swin Transformer 结构来说
各模块的
2. 消除冗余特征
2.1 对于 ViT 结构来说
我们现在有了 decision mask,那么可以有三种方式来实现筛选:
- 直接把 decision score 作为权重对 token 的特征进行加权。
- 根据 decision score 进行排序,将分值较低的 token 丢弃。或者直接将 precision mask 中数值为 0 的 token 丢弃。
- 对要丢弃的 token 特征置零。
为什么不直接把 decision score 作为权重对 token 的特征进行加权? 个人理解,采样能引入一定的随机性。随机性体现在: decision score 的数值即使很大,比如有 0.9 的概率保留当前 token,但在采样过程中,也依然有 0.1 的概率采样结果为丢弃。通过在训练期间引入这种不确定性,能够达到正则化的效果。
为什么不像 TransFG 一样直接丢弃 token? 论文里提到会影响并行性。我的理解是:直接丢弃会导致前后各个模块的 token 数量不一致,这会破坏 attention map、precision mask 等结构和原图在空间上的对应关系。TransFG 只在最后一层进行丢弃操作,前面各层同原图的对应关系没有被破坏,因此还可以通过累乘前面各层的 attention map 来可视化模型的关注区域。
为什么不把丢弃的 token 置零? 论文里提到,即使对特征图置零,置零后的 token 仍然会在经由 attention 对其他 token 产生影响。
因此
模型在训练期间通过影响 attention map 来筛选 token,根据 decision mask,可以构造这样一个矩阵:待丢弃 token 对应列的元素全为 0,待保留 token 对应列的元素全为 1,主对角线保持为1。将这样一个矩阵和 attention map 对应元素相乘,就把待丢弃 token 对应整列的注意力权重全部置为 0 了。最后对 attention map 按行重新做一下归一化(除以整行元素之和)。这种方式既保证了筛选的效果,也保持了特征图的尺寸不变。
模型在推理时则是直接通过 argsort 来筛选 token,因为这时候既不需要考虑可不可微的问题,也不需要考虑随机性的问题,也不用担心和原图的对应关系被破坏。
2.2 对于 Swin Transformer 来说
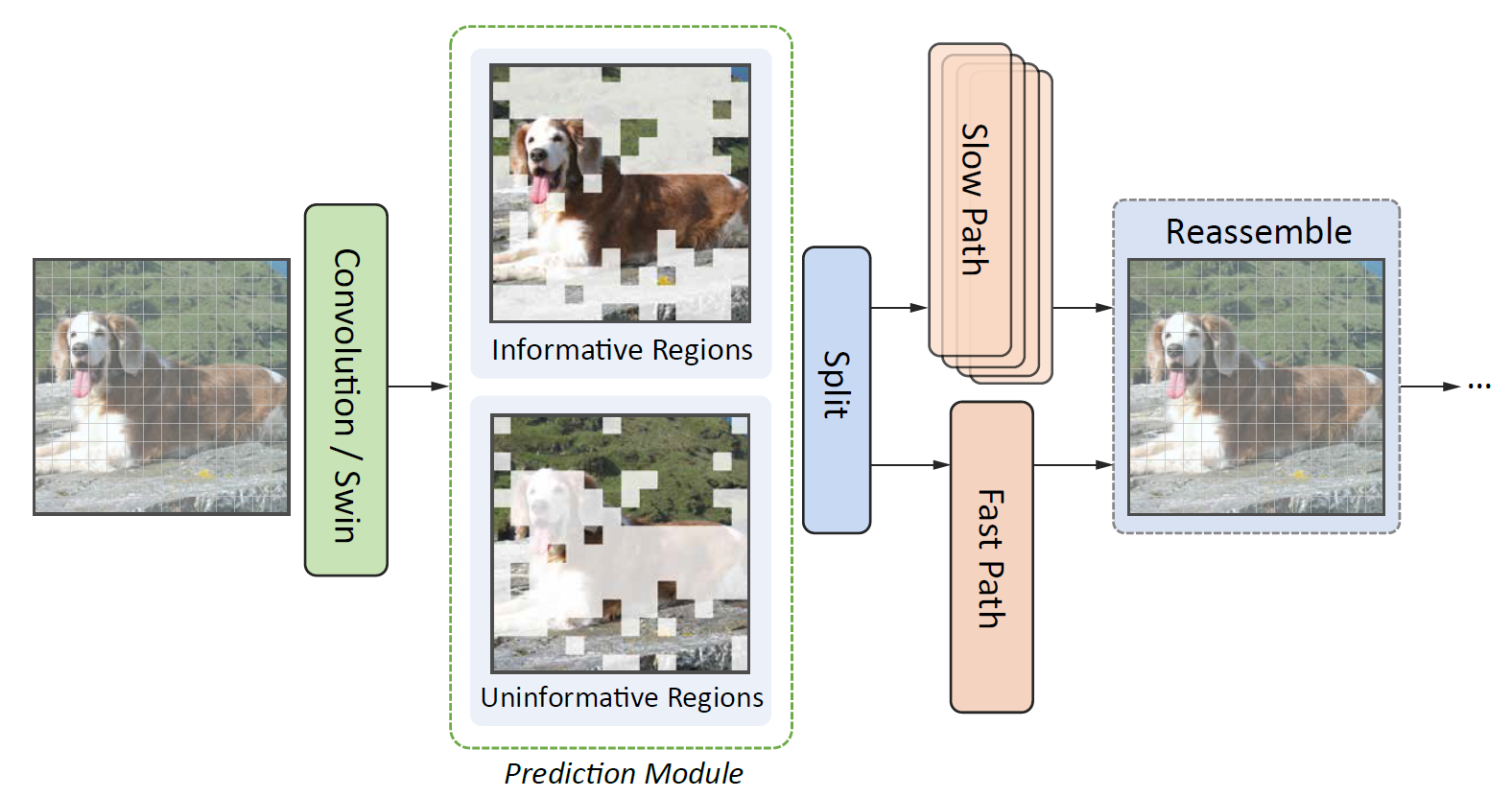
论文没有采用和 DynamicViT 一样的思路,没有对 Swin Transformer 的 attention map 进行干预(可能涉及到滑动窗,考虑起来过于复杂?),而是选择了在 MLP 阶段做改动。
我们现在按照 1.2 的做法得到了 decision mask,论文将 Swin Transformer 原有的 MLP 计算过程视为 slow path,然后建立一个和它平行的 fast path,这个 fast 就体现在模型结构比 slow path 简单(很多)。
通过阅读源码可知,对 Swin Transformer 的 Dynamic 化,只涉及第 3 个 stage,比如各 stage 的 block 数量为 [2, 2, 6, 2],那就只在包含 6 个 block 的这个 stage 引入 decision mask 相关操作。在这个 stage 中,会从第4个 block 起,将原始的 SwinTransformerBlock 改为 AdaSwinTransformerBlock
对于修改后的 block,原有的特征
按照源码的计算过程,当前 block 的
3. 效果
从实验结果上看,DynamicViT 的结果整体表现较好,但对 ConvNeXt 和 Swin Transformer 的 Dynamic 化,并未在分类准确率上表现出优势。不过综合模型的计算复杂度来看,DynamicCNN 和 DynamicSwin 都能明显减少模型的参数量,提高推理速度。